

Feature Engineering Pipeline
In this section, we will create a feature engineering pipeline to perform the following steps:
Load data from Supabase.
Save the raw data locally.
Preprocess the locally stored data.
Save the preprocessed data back to the local directory
Install Essential Libraries
Install the required libraries for the feature engineering pipeline:

Loading Data from Supabase
Before loading data from Supabase, ensure the data exists on the Supabase platform.
Refer to the documentation on how to upload CSV data to Supabase.
Next, copy your Supabase URL and API key into your .env file. We will use the python-dotenv library to load these environment variables.
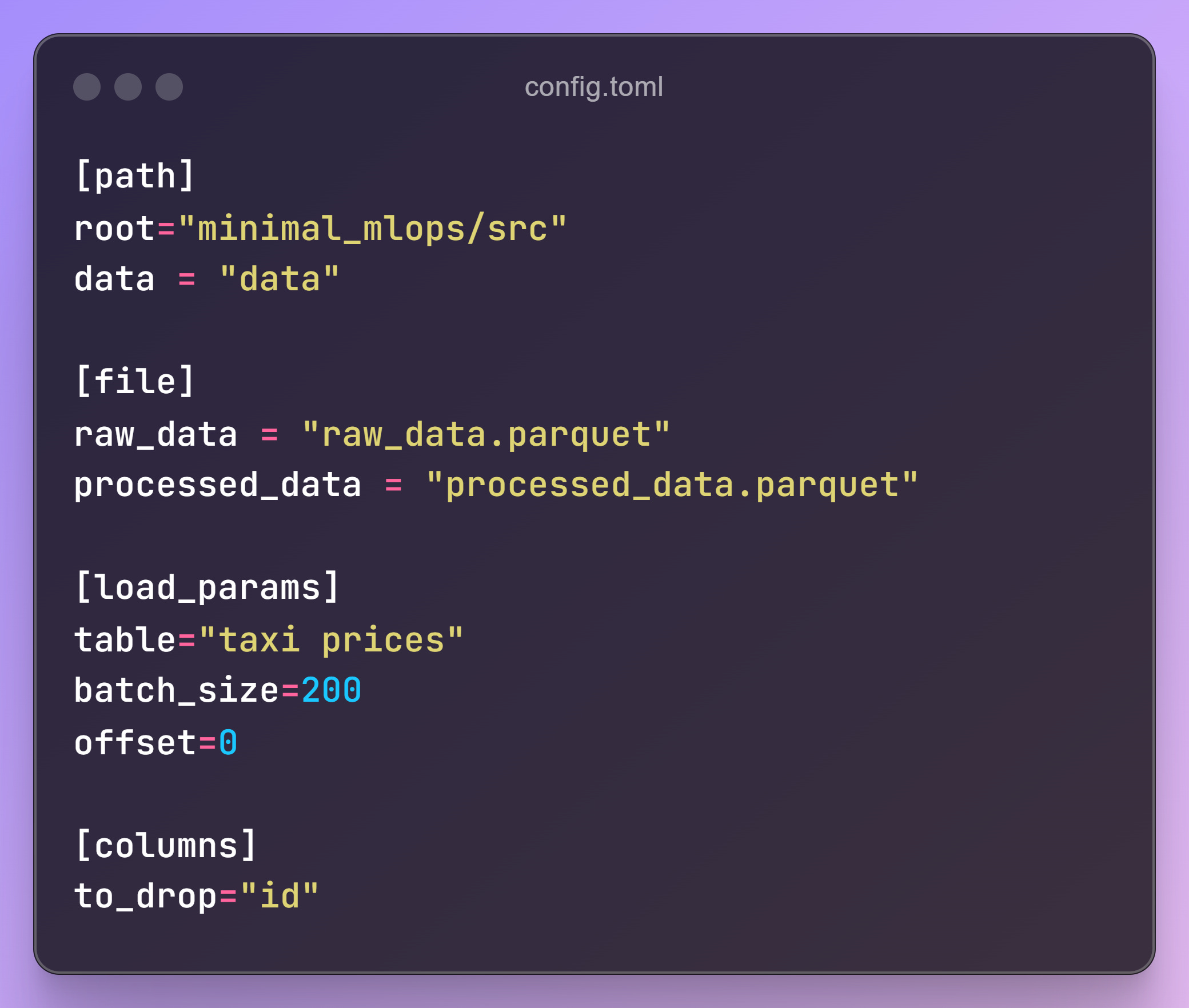
Update your configuration file with the required parameters for the data loading script.
Script Overview
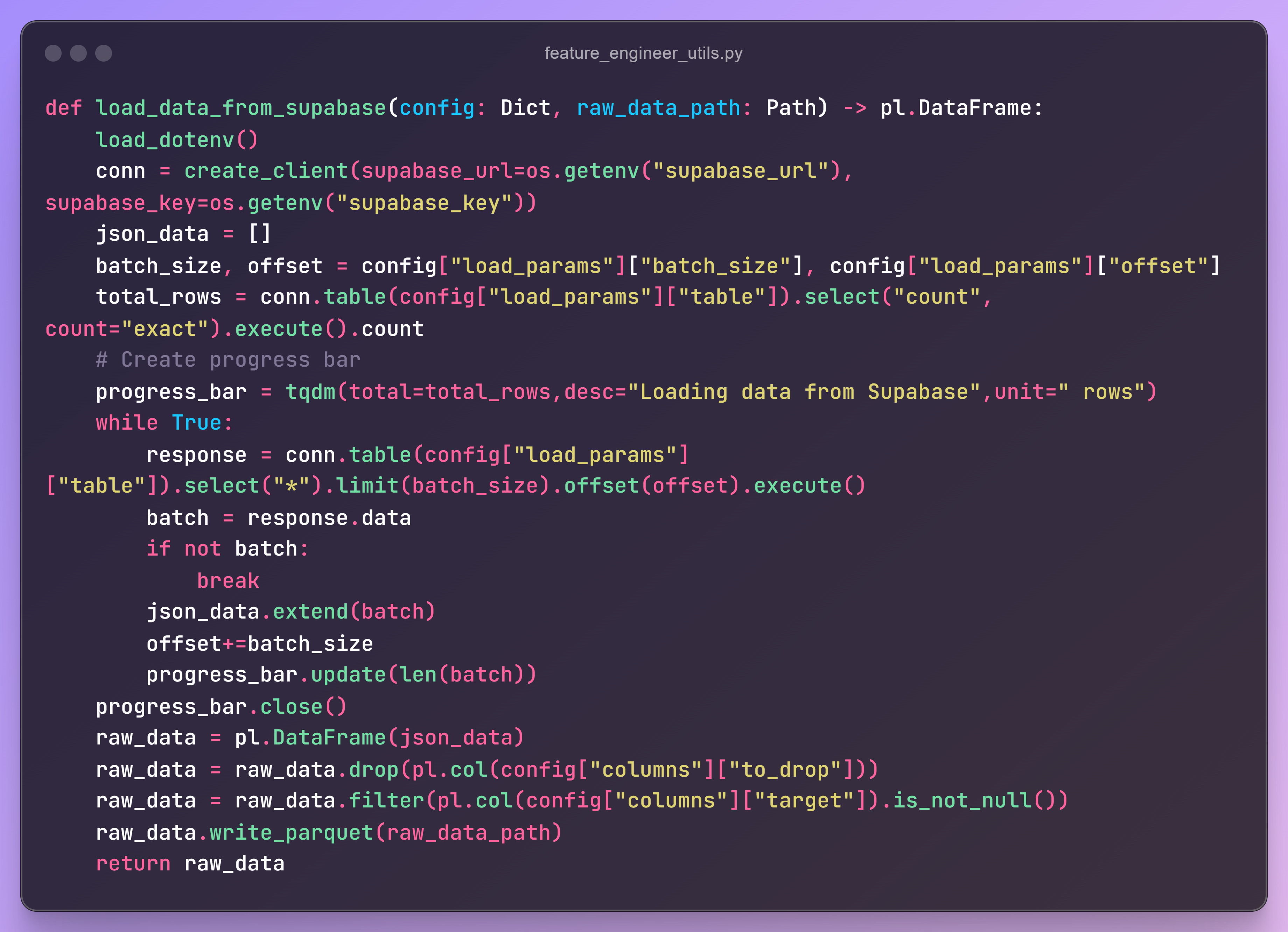
The script for loading data performs the following operations:
Establishes a connection using the Supabase URL and API key.
Fetches data in batches (e.g., 200 records per batch for a dataset with 1,000 records).
Retrieves the total row count using a query.
Iterates through the batches, loading the data as a
polarsDataFrame.Saves the loaded data to the
data/folder.
Refer to the complete script in the GitHub repository for detailed implementation.
Preprocessing the Data
Load and Split Raw Data
Once the raw data is fetched, load it locally from the data/ folder for preprocessing tasks.
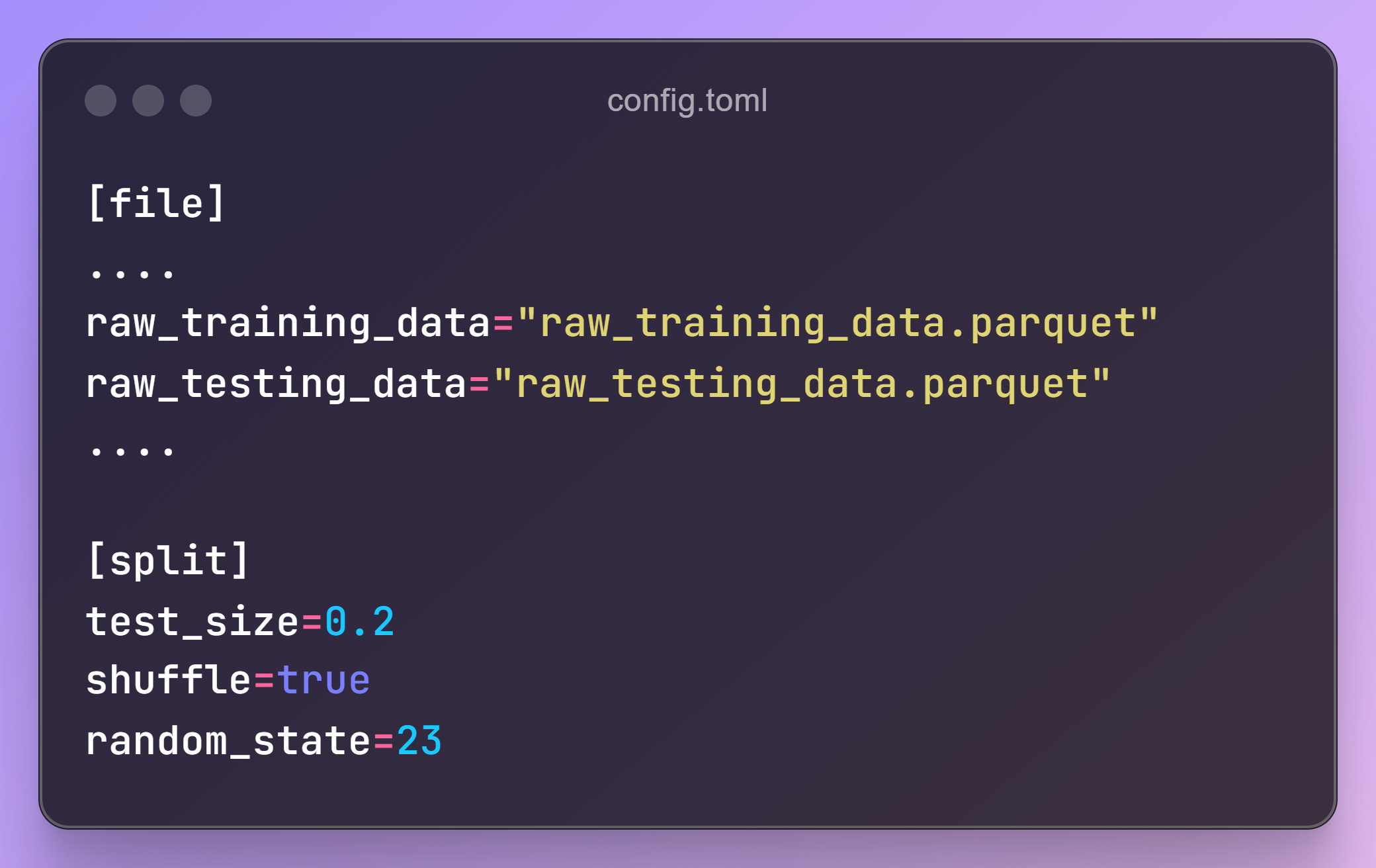
It’s good practice to split the data into training and testing sets before preprocessing.
Update the configuration file with path settings for storing the split data.
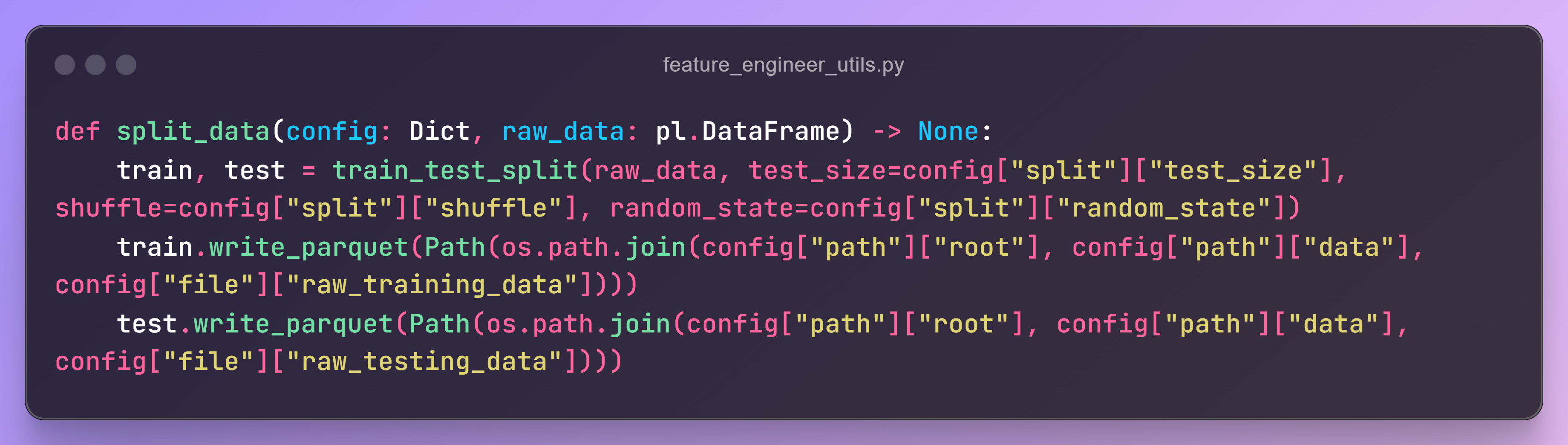
Splitting Script
The script uses scikit-learn’s train_test_split method to divide the data.
Preprocessing Steps
Add configuration details for preprocessing strategies, including:
Lists of numerical, categorical, ordinal, and nominal variables.
Strategies for handling missing values and encoding categorical features.
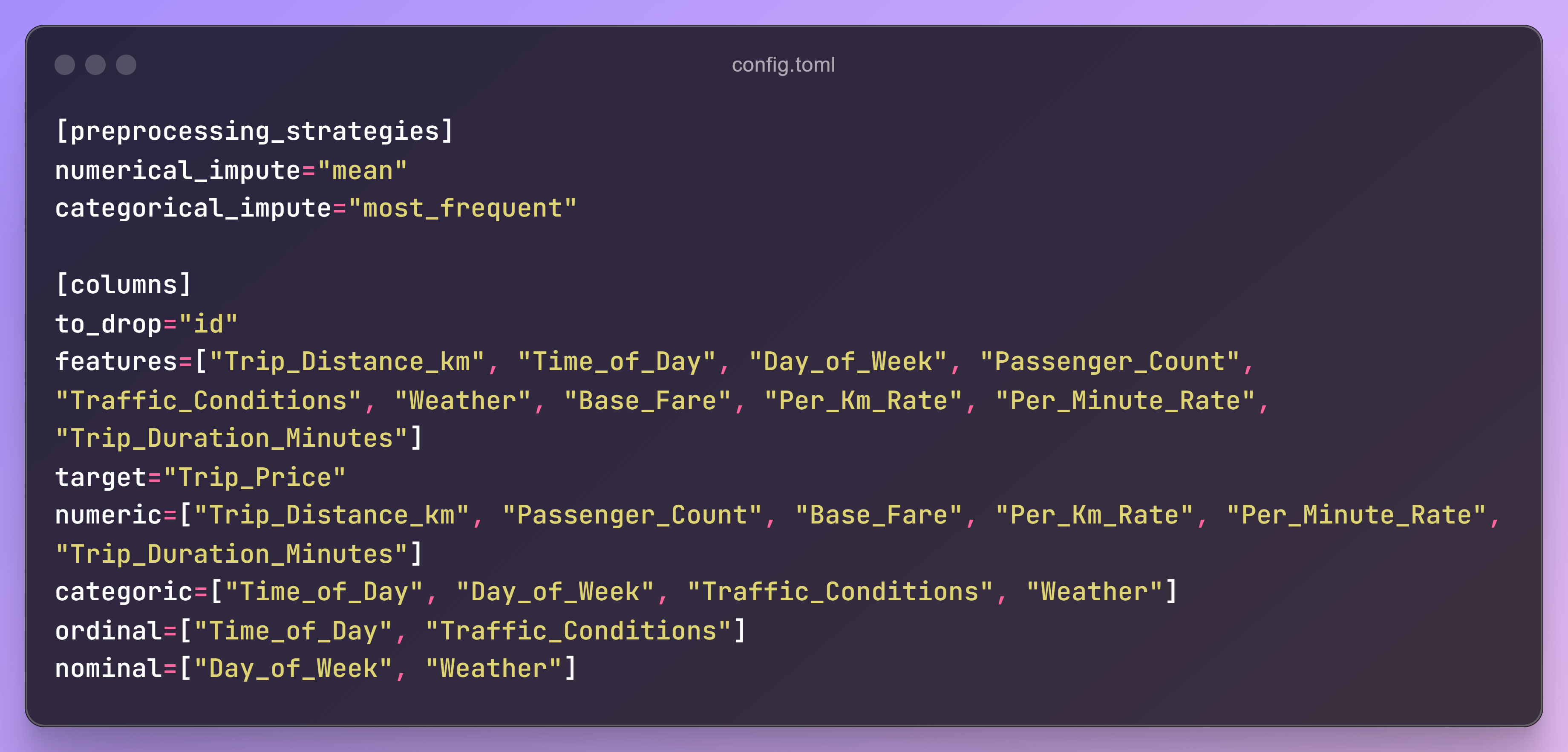
Follow these preprocessing steps:
Imputation:
Use
SimpleImputerwith themeanstrategy for numerical columns.Use
SimpleImputerwith themost_frequentstrategy for categorical columns.
Encoding:
Encode nominal categorical columns using
OneHotEncoder.Encode ordinal categorical columns using
OrdinalEncoder.
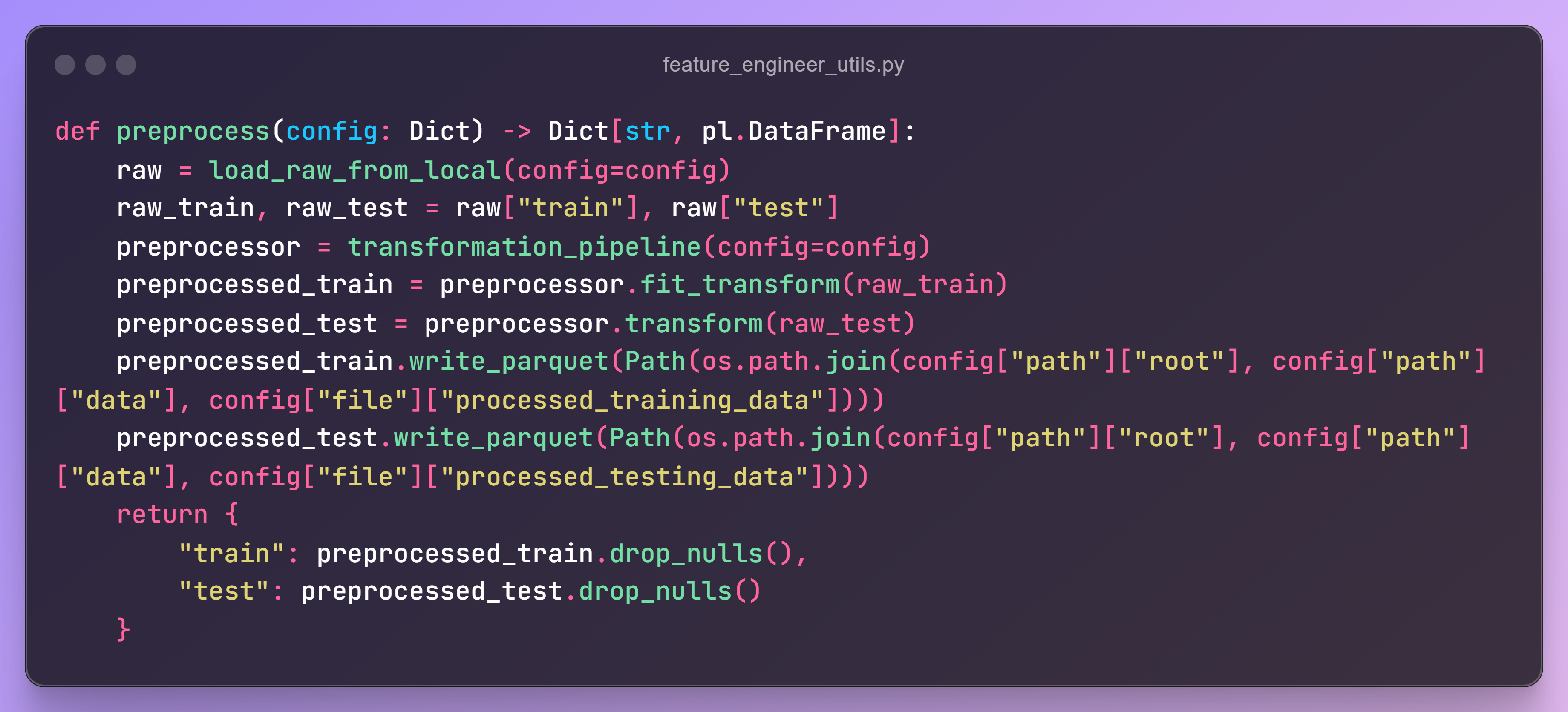
Transformation Pipeline
The pipeline performs all the preprocessing operations in sequence:
Take the raw data as input.
Create a transformation pipeline using
make_pipelineandmake_column_transformer.Fit the pipeline to the raw training and testing data.
Return and save the transformed data.
Transformation Pipeline
The pipeline performs all the preprocessing operations in sequence:
Take the raw data as input.
Create a transformation pipeline using
make_pipelineandmake_column_transformer.Fit the pipeline to the raw training and testing data.
Return and save the transformed data.
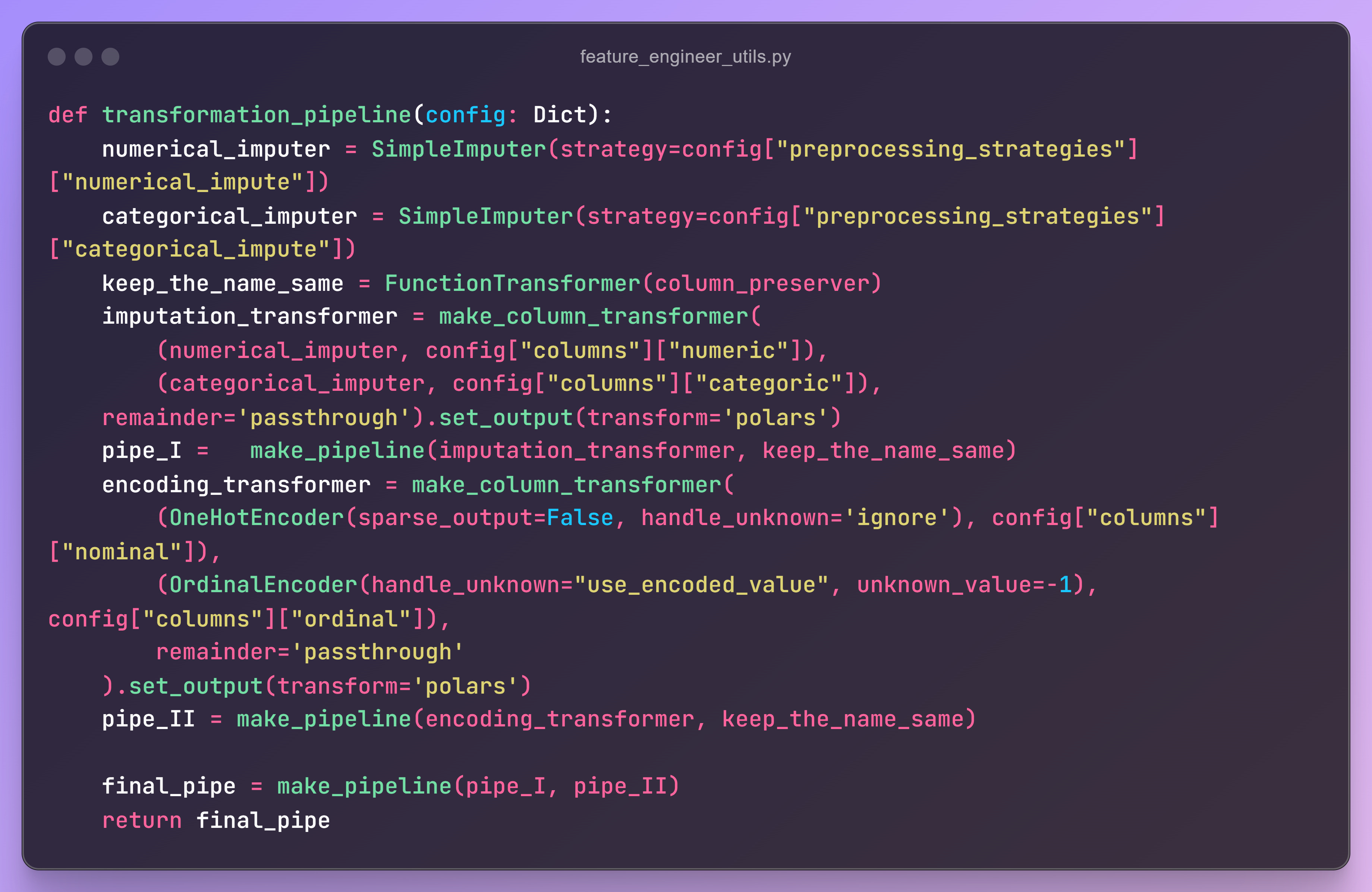
How the Transformation Pipeline Works
This pipeline is integrated into a feature engineering class, which ensures a modular and reusable structure.
For the full implementation and how to use these functions, refer to the GitHub repository.